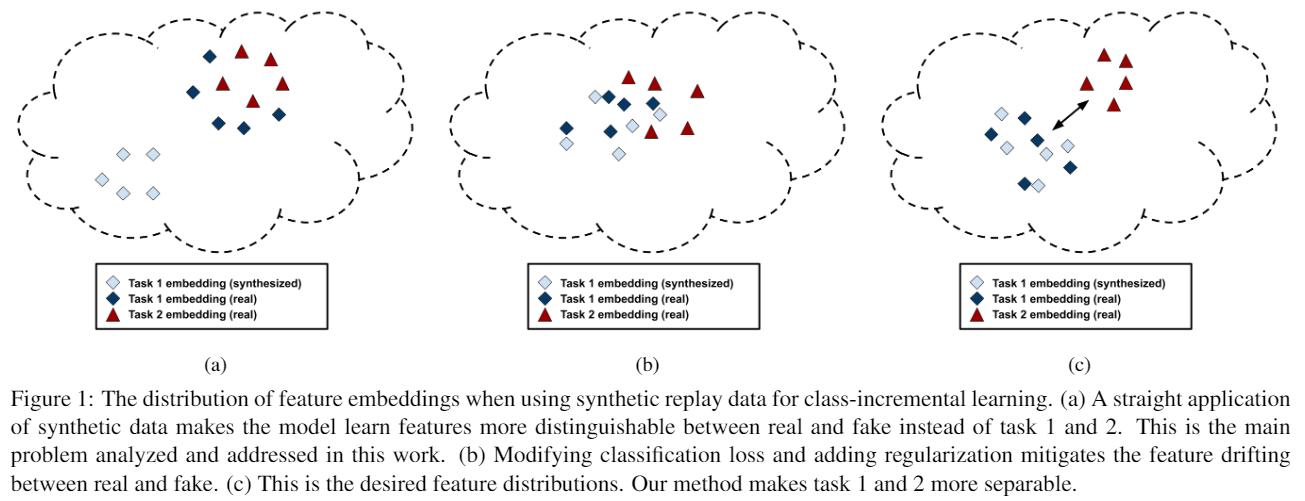
In our work, we consider the high-impact problem of Data-Free Class-Incremental Learning (DFCIL), where an agent must learn new concepts over time without storing generators or training data from past tasks. The impact of solving this problem is reducing memory budget and eliminating private data storage for incremental learning applications (healthcare, autonomous vehicles, etc).
One approach for DFCIL is to replay synthetic images produced by inverting a frozen copy of an agent’s classification model. Unfortunately, we show that the feature embeddings learned with this approach prioritizes domain over semantics. Specifically, we reason that when training a model with real images from the current task and synthetic images representing the past tasks, the feature extraction model causes the feature distributions of real images from the past tasks (which are not available during training) to be close in the feature space to the real images from the current task and far in the feature space from the synthetic images. This phenomena, visualized below, causes a bias for the model to falsely predict real images from the previous tasks with current task labels.
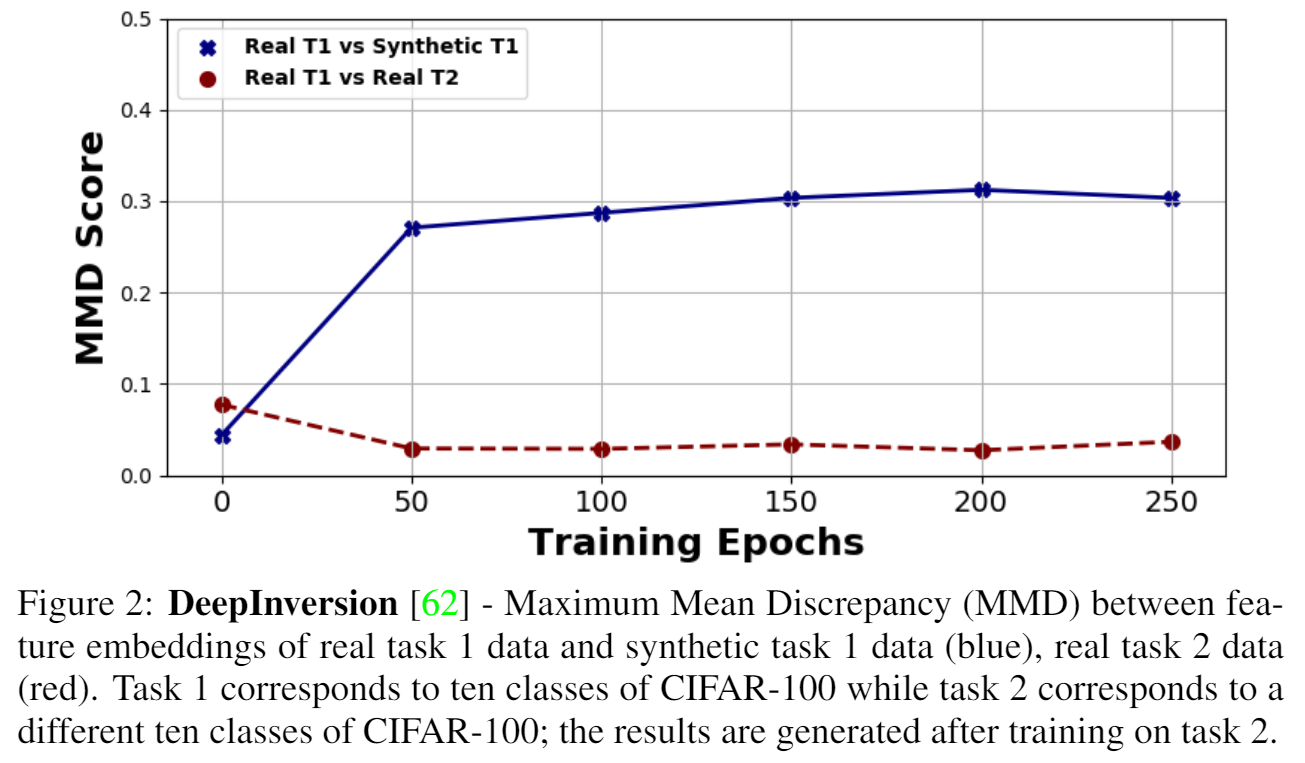
To address this issue, we propose a novel class-incremental learning method which learns features for the new task with a local classification loss which excludes the synthetic data and past-task linear heads, instead relying on importance-weighted feature distillation and linear head fine-tuning to separate feature embeddings of the new and past tasks.
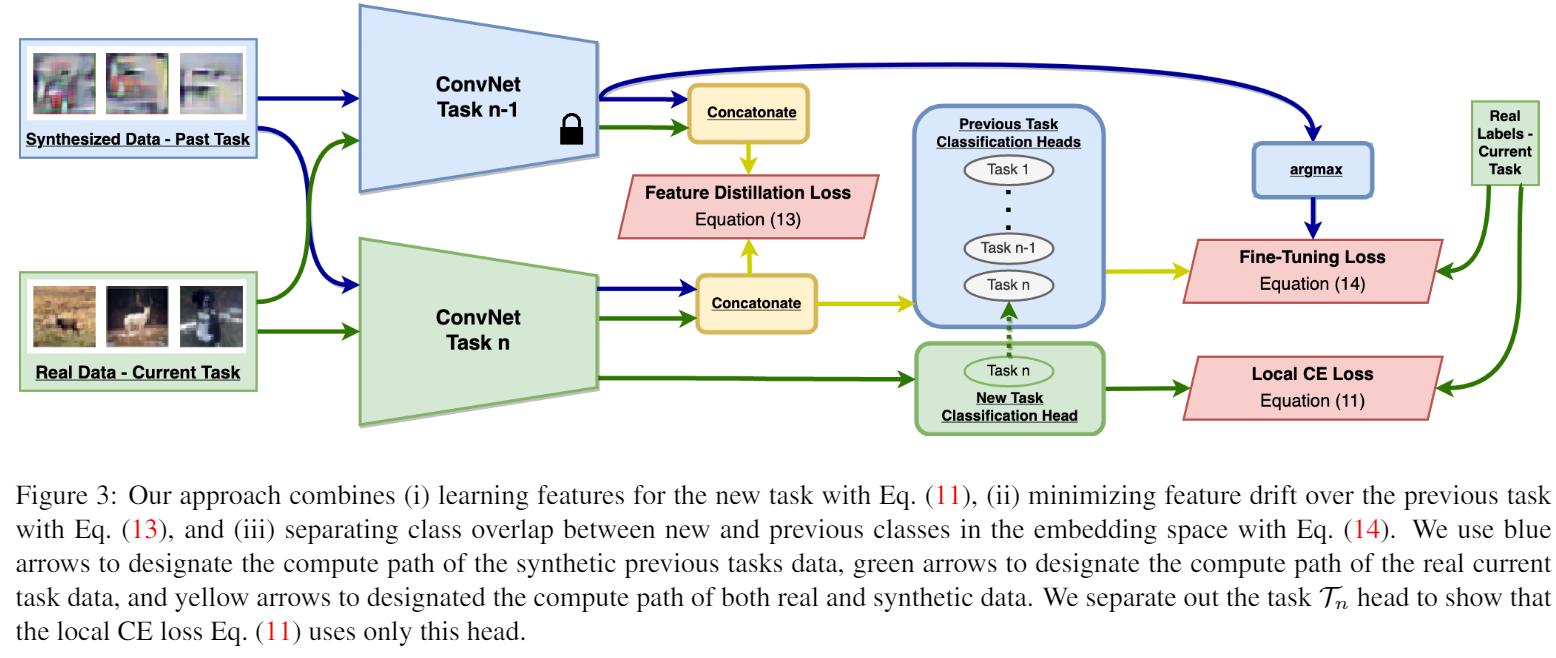
We show that our feature embedding prioritizes semantics over domain.
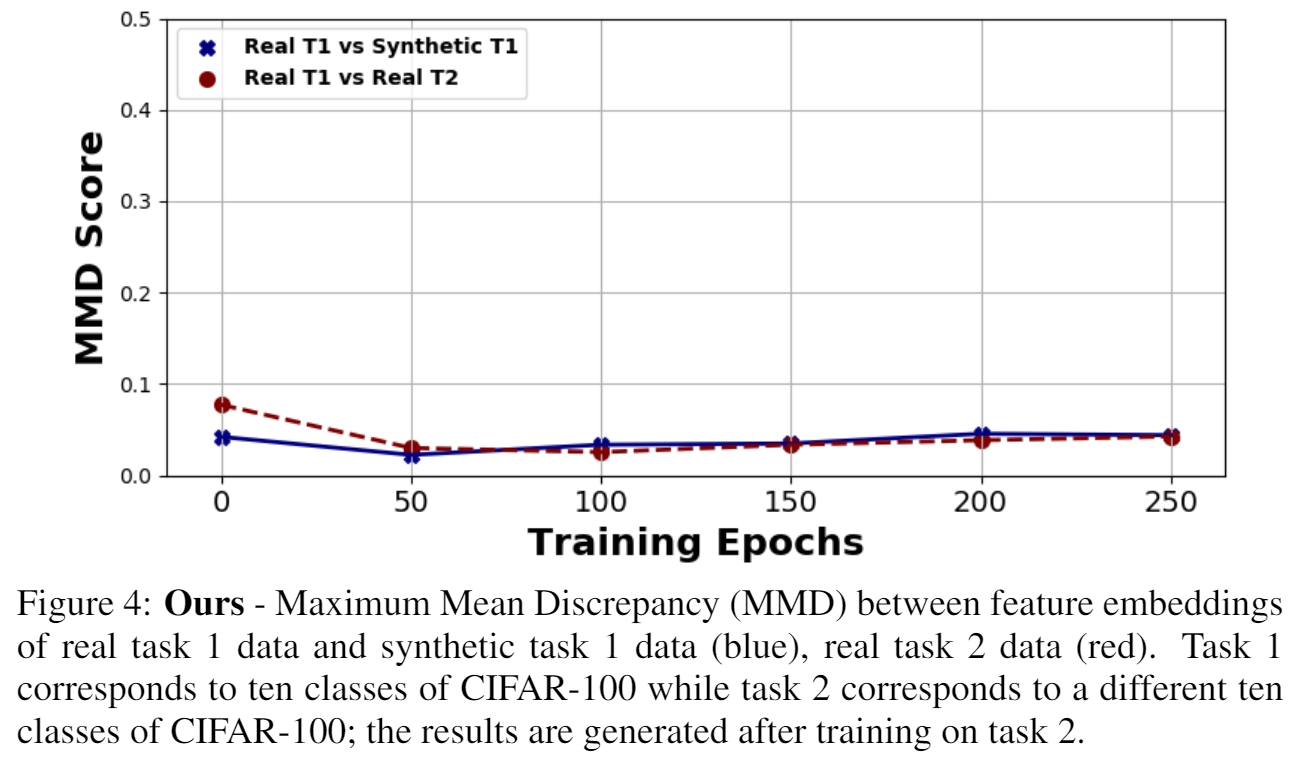
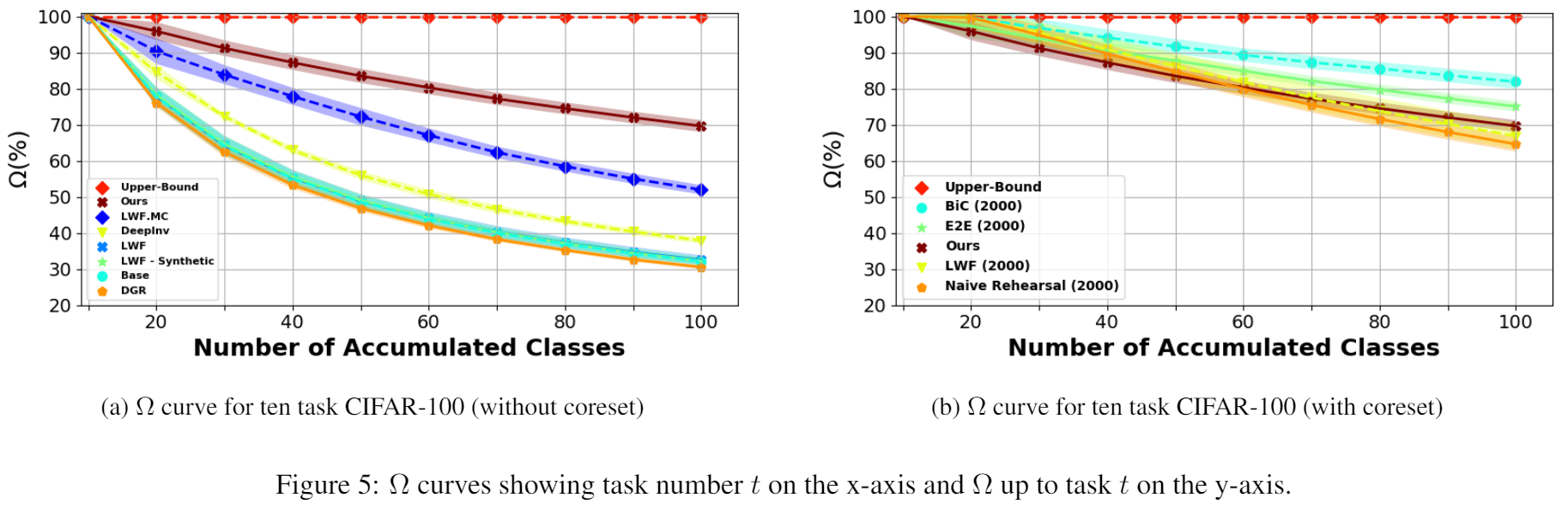
Experiments demonstrate that our method represents the new state of the art for the DFCIL setting, resulting in up to a 25.1% increase in final task accuracy (absolute difference) compared to DeepInversion for common class-incremental benchmarks, and even outperforms popular replay baselines Naive Rehearsal and LwF with a coreset.
Thank you for reading! Please read our full text to learn more.