Abstract
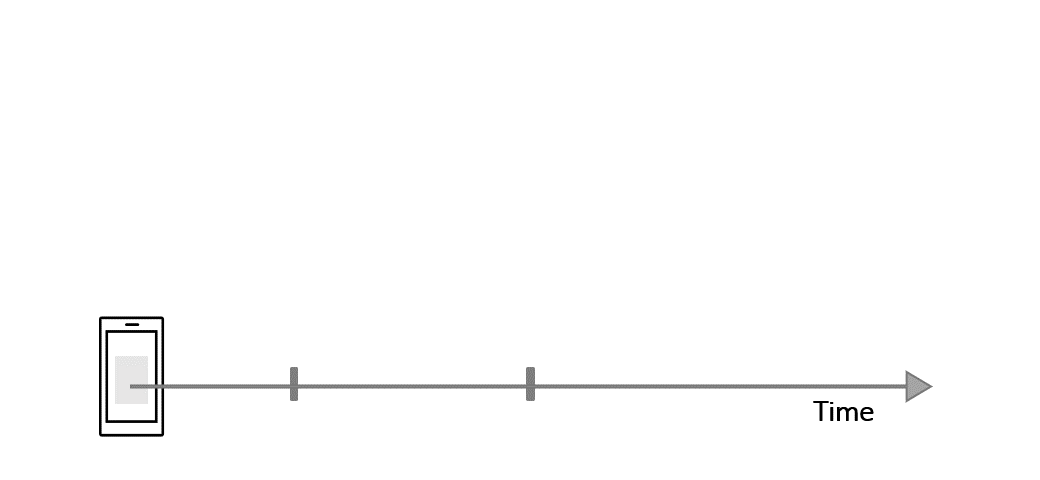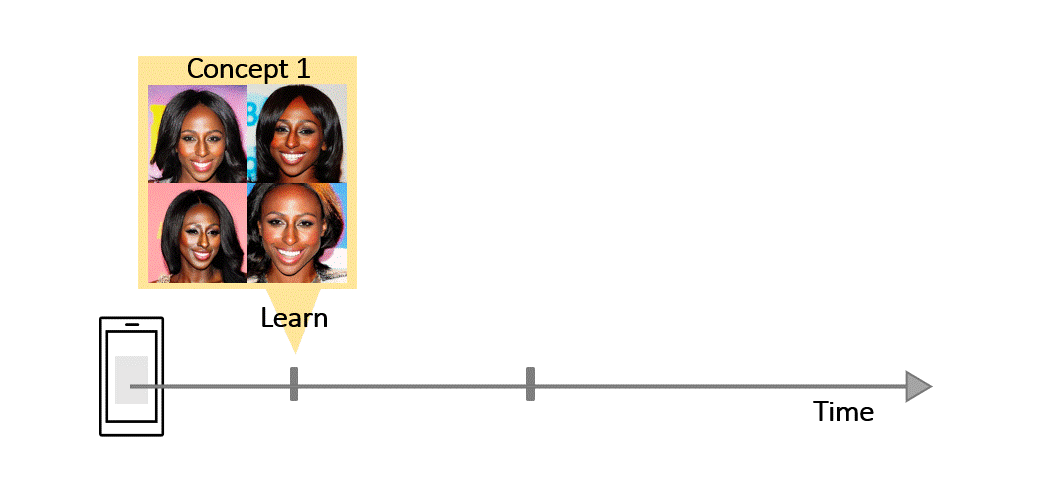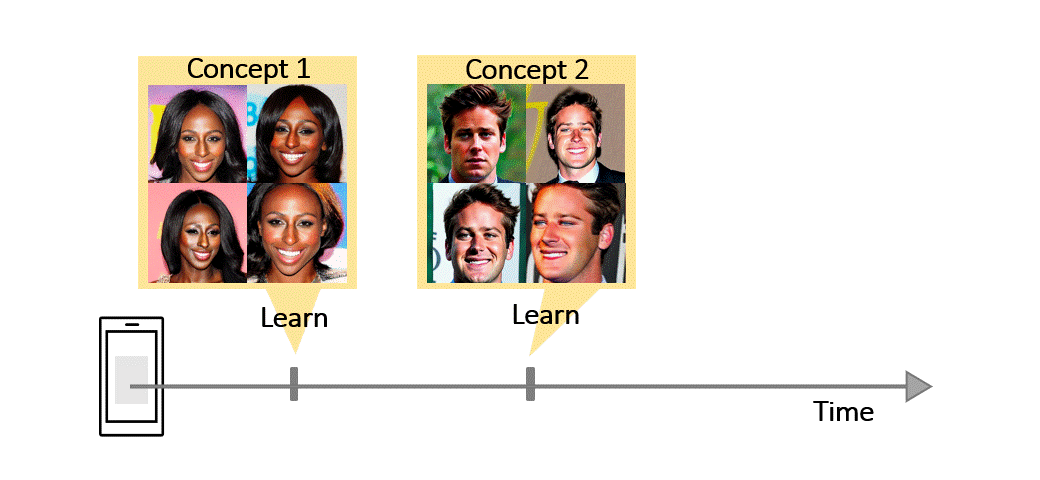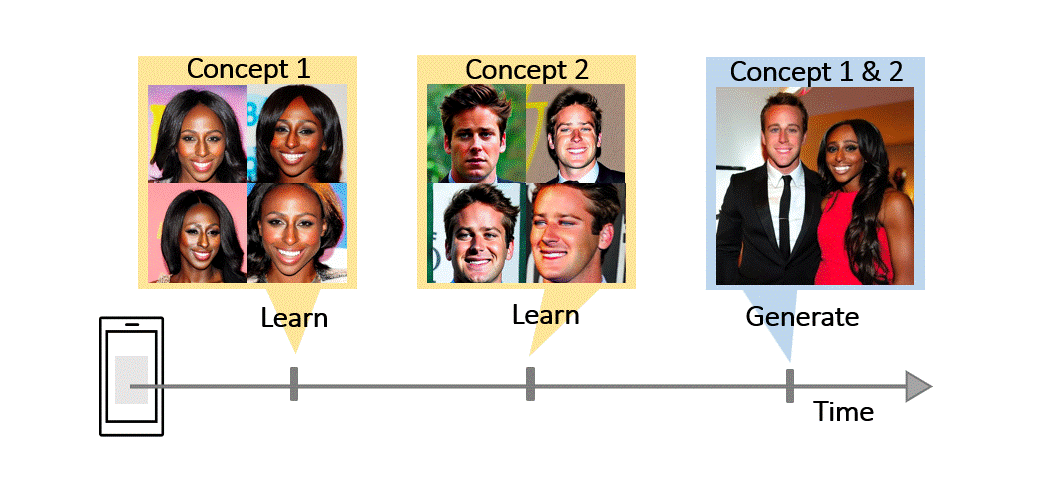
Recent works demonstrate a remarkable ability to customize text-to-image diffusion models while only providing a few example images. What happens if you try to customize such models using multiple, fine-grained concepts in a sequential (i.e., continual) manner? In our work, we show that recent state-of-the-art customization of text-to-image models suffer from catastrophic forgetting when new concepts arrive sequentially. Specifically, when adding a new concept, the ability to generate high quality images of past, similar concepts degrade. To circumvent this forgetting, we propose a new method, C-LoRA, composed of a continually self-regularized low-rank adaptation in cross attention layers of the popular Stable Diffusion model. Furthermore, we use customization prompts which do not include the word of the customized object (i.e., person
for a human face dataset) and are initialized as completely random embeddings. Importantly, our method induces only marginal additional parameter costs and requires no storage of user data for replay. We show that C-LoRA not only outperforms several baselines for our proposed setting of text-to-image continual customization, which we refer to as Continual Diffusion, but that we achieve a new state-of-the-art in the well-established rehearsal-free continual learning setting for image classification. The high achieving performance of C-LoRA in two separate domains positions it as a compelling solution for a wide range of applications, and we believe it has significant potential for practical impact.
Method
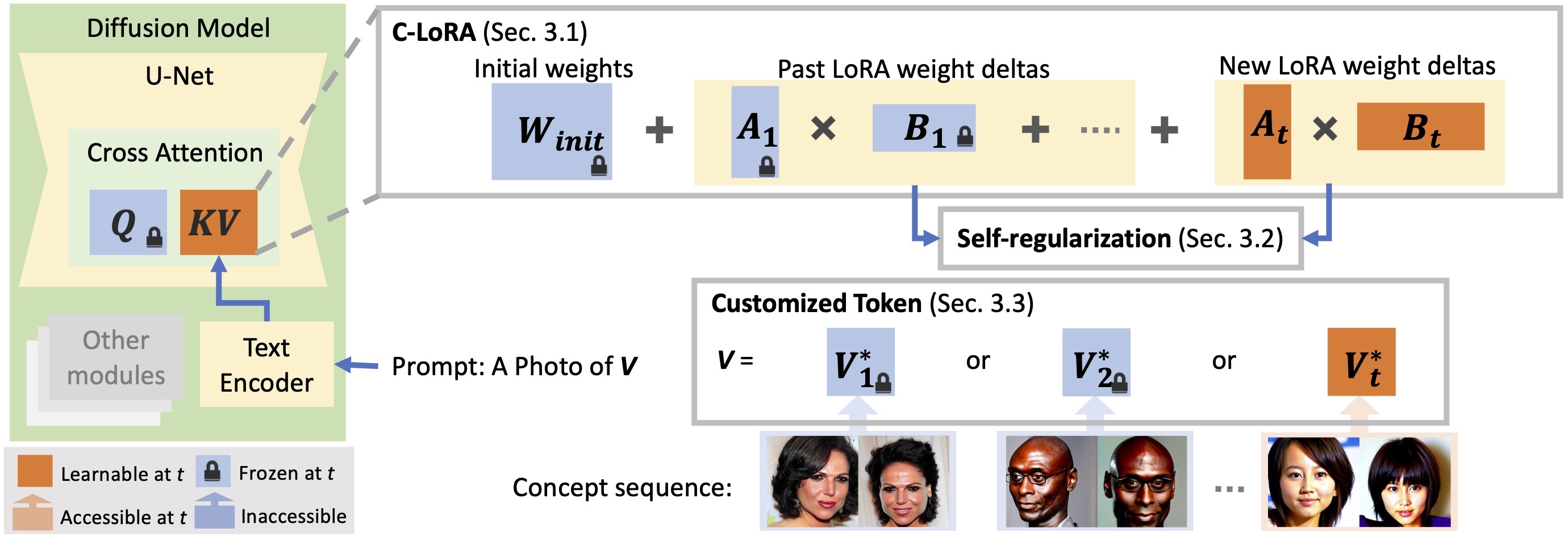
person) from the prompt.
Results: Faces


Results: Landmarks

BibTeX
@article{smith2024continualdiffusion,
title={Continual Diffusion: Continual Customization of Text-to-Image Diffusion with C-LoRA},
author={Smith, James Seale and Hsu, Yen-Chang and Zhang, Lingyu and Hua, Ting and Kira, Zsolt and Shen, Yilin and Jin, Hongxia},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2024}
}